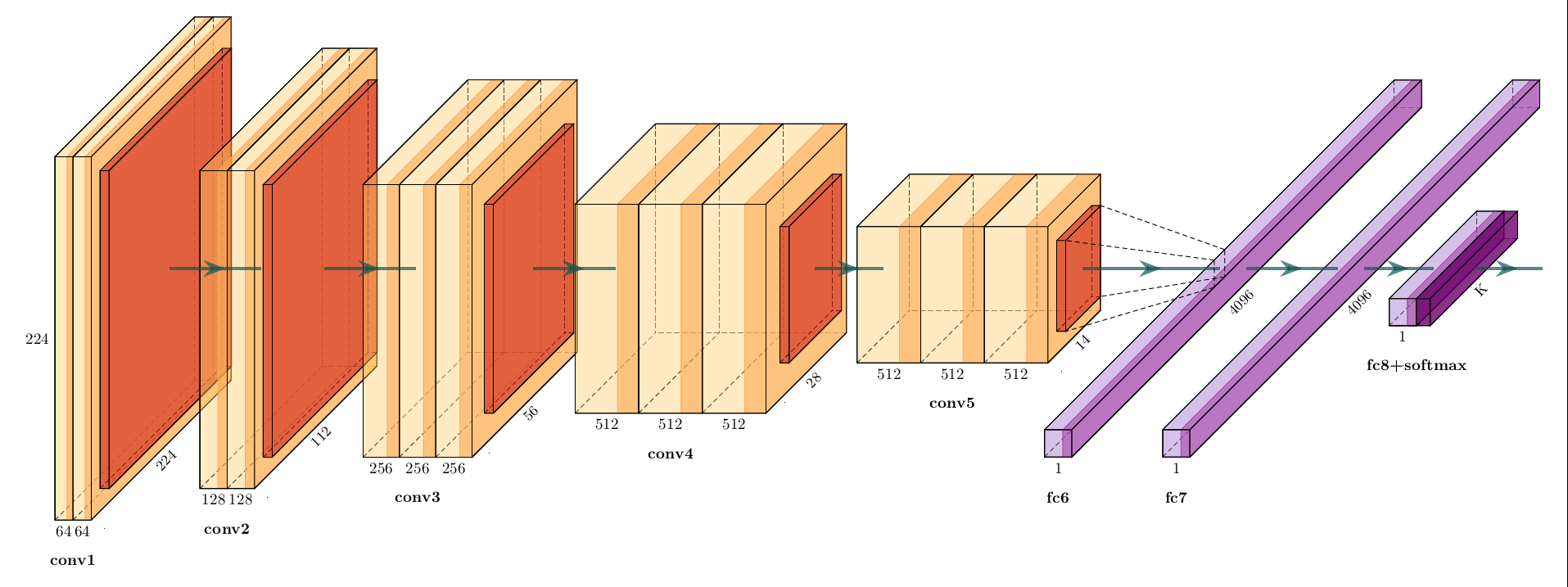
VGGFace是牛津大学视觉组于2015年发表,VGGNet也是他们提出的,是基于VGGNet的人脸识别模型。
为什么不能在pytorch上丝滑使用vggface
首先,vggface是基于vgg16架构的,pytorch本身也提供了vgg16等预训练模型(categories是imagenet_classes),见VGG-NETS。
但是pytorch没有针对vggface数据集训练的vggface的预训练模型,你可以在官网的下载处看到提供的如下几种格式:
- vgg_face_matconvnet.tar.gz: Face detection and VGG Face descriptor source code and models (MatConvNet)
- vgg_face_torch.tar.gz: VGG Face descriptor source code and models (Torch)
- vgg_face_caffe.tar.gz: VGG Face descriptor source code and models (Caffe)
也许你会想,这不是有Torch格式的预训练模型吗? 如果进行尝试,会发现是不行的。
困难的真正原因是,之前的torch是使用lua语言,之后在2017年根据python重构了代码变成pytorch,而vgg-face的作者提供的是torch模型,而不是pytorch的模型。VGGface2是支持的(但vggface2数据集已经寄了),还是因为vggface有些年份了。
实践
所以问题,出现了 : pytorch 如何获得预训练模型
过去有
from torch.utils.serialization import load_lua
x = load_lua('x.t7')
但pytorch在1.0之后删除了torch.utils.serialization,目前可以通过torchfile.load读取,但会报错:
TypeError: unhashable type: 'numpy.ndarray'
As of PyTorch 1.0 torch.utils.serialization is completely removed. Hence no one can import models from Lua Torch into PyTorch anymore. Instead, I would suggest installing PyTorch 0.4.1 through pip in a conda environment (so that you can remove it after this) and use this repo to convert your Lua Torch model to PyTorch model, not just the torch.nn.legacy model that you cannot use for training. Then use PyTorch 1.xx to do whatever with it. You can also train your converted Lua Torch models in PyTorch this way :) 来源
但尝试失败,包括之后尝试的三个github的repo:PyVGGFace 、convert_torch_to_pytorch和 vgg-face.pytorch(issue中作者提到他仍能在linux中运行(今年8月)),希望转化成能用的形式,均因为相同的原因失败。
发现网页Samuel Albanie,能下载网络框架的py文件,但不能下载含有权重信息的.pth文件(也可以不去下,底下完整代码里有这玩意)
尝试使用GitHub上的caffemodel2pytorch(这玩意获得proto是通过request的,本地的prototxt文件读不进去)和Caffe2Pytorch(易用,但是0.4.1以上版本没有torch.legacy,而使用anaconda激活的虚拟环境中,pytorch0.4.1报错No module named “caffe”)
依着上面提到的vgg-face.pytorch的issue的思路,使用自己电脑的Ubuntu子系统使用PyVGGFace,成功得到权重文件vggface.pth
链接: https://pan.baidu.com/s/1J8MbHZufFP2IRxUocomUxw?pwd=1wt6 提取码: 1wt6
如何将权重载入到模型框架里?
如果直接使用torch.load导入:
model = torch.load(r"D:\Dataset\models\vggface.pth")
model.eval()
AttributeError: 'collections.OrderedDict' object has no attribute 'eval'
原因是这仅是字典形式的权重数据,没有模型的实体。想用来自Samuel Albanie的模型框架文件获得转化后的权重数据,报错如下,可以看出是字典的键值不匹配。
RuntimeError: Error(s) in loading state_dict for Vgg_face_dag:
Missing key(s) in state_dict: "conv_1_1.weight", "conv_1_1.bias", "conv1_2.weight", "conv1_2.bias", "conv2_1.weight", "conv2_1.bias", "conv2_2.weight", "conv2_2.bias", "conv3_1.weight", "conv3_1.bias", "conv3_2.weight", "conv3_2.bias", "conv3_3.weight", "conv3_3.bias", "conv4_1.weight", "conv4_1.bias", "conv4_2.weight", "conv4_2.bias", "conv4_3.weight", "conv4_3.bias", "conv5_1.weight", "conv5_1.bias", "conv5_2.weight", "conv5_2.bias", "conv5_3.weight", "conv5_3.bias", "fc6.weight", "fc6.bias", "fc7.weight", "fc7.bias", "fc8.weight", "fc8.bias".
Unexpected key(s) in state_dict: "features.conv_1_1.weight", "features.conv_1_1.bias", "features.conv_1_2.weight", "features.conv_1_2.bias", "features.conv_2_1.weight", "features.conv_2_1.bias", "features.conv_2_2.weight", "features.conv_2_2.bias", "features.conv_3_1.weight", "features.conv_3_1.bias", "features.conv_3_2.weight", "features.conv_3_2.bias", "features.conv_3_3.weight", "features.conv_3_3.bias", "features.conv_4_1.weight", "features.conv_4_1.bias", "features.conv_4_2.weight", "features.conv_4_2.bias", "features.conv_4_3.weight", "features.conv_4_3.bias", "features.conv_5_1.weight", "features.conv_5_1.bias", "features.conv_5_2.weight", "features.conv_5_2.bias", "features.conv_5_3.weight", "features.conv_5_3.bias", "fc.fc6.weight", "fc.fc6.bias", "fc.fc7.weight", "fc.fc7.bias", "fc.fc8.weight", "fc.fc8.bias".
实测不能通过在定义层时在conv前添加features.xxx解决
self.add_module("features.conv_1_1",nn.Conv2d(3, 64, kernel_size=[3, 3], stride=(1, 1), padding=(1, 1)))
KeyError: 'module name can\'t contain ".", got: features.conv_1_1'
写函数,得到新字典后成功获得完整模型实例
def transform_key(model):
#列表来自报错内容,可复制进来更改,创建一个新字典,将key 从post_names -> names
names = ["conv_1_1.weight", "conv_1_1.bias", "conv1_2.weight", "conv1_2.bias", "conv2_1.weight", "conv2_1.bias", "conv2_2.weight", "conv2_2.bias", "conv3_1.weight", "conv3_1.bias", "conv3_2.weight", "conv3_2.bias", "conv3_3.weight", "conv3_3.bias", "conv4_1.weight", "conv4_1.bias", "conv4_2.weight", "conv4_2.bias", "conv4_3.weight", "conv4_3.bias", "conv5_1.weight", "conv5_1.bias", "conv5_2.weight", "conv5_2.bias", "conv5_3.weight", "conv5_3.bias", "fc6.weight", "fc6.bias", "fc7.weight", "fc7.bias", "fc8.weight", "fc8.bias"]
post_names = ["features.conv_1_1.weight", "features.conv_1_1.bias", "features.conv_1_2.weight", "features.conv_1_2.bias", "features.conv_2_1.weight", "features.conv_2_1.bias", "features.conv_2_2.weight", "features.conv_2_2.bias", "features.conv_3_1.weight", "features.conv_3_1.bias", "features.conv_3_2.weight", "features.conv_3_2.bias", "features.conv_3_3.weight", "features.conv_3_3.bias", "features.conv_4_1.weight", "features.conv_4_1.bias", "features.conv_4_2.weight", "features.conv_4_2.bias", "features.conv_4_3.weight", "features.conv_4_3.bias", "features.conv_5_1.weight", "features.conv_5_1.bias", "features.conv_5_2.weight", "features.conv_5_2.bias", "features.conv_5_3.weight", "features.conv_5_3.bias", "fc.fc6.weight", "fc.fc6.bias", "fc.fc7.weight", "fc.fc7.bias", "fc.fc8.weight", "fc.fc8.bias"]
from collections import OrderedDict
new_state_dict = OrderedDict()
for i in range(0,len(model)):
name = names[i]
new_state_dict[name] = model[post_names[i]]
return new_state_dict
完整代码
import torch
import torch.nn as nn
class Vgg_face_dag(nn.Module):
def __init__(self):
super(Vgg_face_dag, self).__init__()
self.meta = {'mean': [129.186279296875, 104.76238250732422, 93.59396362304688],
'std': [1, 1, 1],
'imageSize': [224, 224, 3]}
self.conv1_1 = nn.Conv2d(3, 64, kernel_size=[3, 3], stride=(1, 1), padding=(1, 1))
self.relu1_1 = nn.ReLU(inplace=True)
self.conv1_2 = nn.Conv2d(64, 64, kernel_size=[3, 3], stride=(1, 1), padding=(1, 1))
self.relu1_2 = nn.ReLU(inplace=True)
self.pool1 = nn.MaxPool2d(kernel_size=[2, 2], stride=[2, 2], padding=0, dilation=1, ceil_mode=False)
self.conv2_1 = nn.Conv2d(64, 128, kernel_size=[3, 3], stride=(1, 1), padding=(1, 1))
self.relu2_1 = nn.ReLU(inplace=True)
self.conv2_2 = nn.Conv2d(128, 128, kernel_size=[3, 3], stride=(1, 1), padding=(1, 1))
self.relu2_2 = nn.ReLU(inplace=True)
self.pool2 = nn.MaxPool2d(kernel_size=[2, 2], stride=[2, 2], padding=0, dilation=1, ceil_mode=False)
self.conv3_1 = nn.Conv2d(128, 256, kernel_size=[3, 3], stride=(1, 1), padding=(1, 1))
self.relu3_1 = nn.ReLU(inplace=True)
self.conv3_2 = nn.Conv2d(256, 256, kernel_size=[3, 3], stride=(1, 1), padding=(1, 1))
self.relu3_2 = nn.ReLU(inplace=True)
self.conv3_3 = nn.Conv2d(256, 256, kernel_size=[3, 3], stride=(1, 1), padding=(1, 1))
self.relu3_3 = nn.ReLU(inplace=True)
self.pool3 = nn.MaxPool2d(kernel_size=[2, 2], stride=[2, 2], padding=0, dilation=1, ceil_mode=False)
self.conv4_1 = nn.Conv2d(256, 512, kernel_size=[3, 3], stride=(1, 1), padding=(1, 1))
self.relu4_1 = nn.ReLU(inplace=True)
self.conv4_2 = nn.Conv2d(512, 512, kernel_size=[3, 3], stride=(1, 1), padding=(1, 1))
self.relu4_2 = nn.ReLU(inplace=True)
self.conv4_3 = nn.Conv2d(512, 512, kernel_size=[3, 3], stride=(1, 1), padding=(1, 1))
self.relu4_3 = nn.ReLU(inplace=True)
self.pool4 = nn.MaxPool2d(kernel_size=[2, 2], stride=[2, 2], padding=0, dilation=1, ceil_mode=False)
self.conv5_1 = nn.Conv2d(512, 512, kernel_size=[3, 3], stride=(1, 1), padding=(1, 1))
self.relu5_1 = nn.ReLU(inplace=True)
self.conv5_2 = nn.Conv2d(512, 512, kernel_size=[3, 3], stride=(1, 1), padding=(1, 1))
self.relu5_2 = nn.ReLU(inplace=True)
self.conv5_3 = nn.Conv2d(512, 512, kernel_size=[3, 3], stride=(1, 1), padding=(1, 1))
self.relu5_3 = nn.ReLU(inplace=True)
self.pool5 = nn.MaxPool2d(kernel_size=[2, 2], stride=[2, 2], padding=0, dilation=1, ceil_mode=False)
self.fc6 = nn.Linear(in_features=25088, out_features=4096, bias=True)
self.relu6 = nn.ReLU(inplace=True)
self.dropout6 = nn.Dropout(p=0.5)
self.fc7 = nn.Linear(in_features=4096, out_features=4096, bias=True)
self.relu7 = nn.ReLU(inplace=True)
self.dropout7 = nn.Dropout(p=0.5)
self.fc8 = nn.Linear(in_features=4096, out_features=2622, bias=True)
def forward(self, x0):
x1 = self.conv1_1(x0)
x2 = self.relu1_1(x1)
x3 = self.conv1_2(x2)
x4 = self.relu1_2(x3)
x5 = self.pool1(x4)
x6 = self.conv2_1(x5)
x7 = self.relu2_1(x6)
x8 = self.conv2_2(x7)
x9 = self.relu2_2(x8)
x10 = self.pool2(x9)
x11 = self.conv3_1(x10)
x12 = self.relu3_1(x11)
x13 = self.conv3_2(x12)
x14 = self.relu3_2(x13)
x15 = self.conv3_3(x14)
x16 = self.relu3_3(x15)
x17 = self.pool3(x16)
x18 = self.conv4_1(x17)
x19 = self.relu4_1(x18)
x20 = self.conv4_2(x19)
x21 = self.relu4_2(x20)
x22 = self.conv4_3(x21)
x23 = self.relu4_3(x22)
x24 = self.pool4(x23)
x25 = self.conv5_1(x24)
x26 = self.relu5_1(x25)
x27 = self.conv5_2(x26)
x28 = self.relu5_2(x27)
x29 = self.conv5_3(x28)
x30 = self.relu5_3(x29)
x31_preflatten = self.pool5(x30)
x31 = x31_preflatten.view(x31_preflatten.size(0), -1)
x32 = self.fc6(x31)
x33 = self.relu6(x32)
x34 = self.dropout6(x33)
x35 = self.fc7(x34)
x36 = self.relu7(x35)
x37 = self.dropout7(x36)
x38 = self.fc8(x37)
return x38
def transform_key(state_dict):
#列表来自报错内容,可复制进来更改,创建一个新字典,将key 从post_names -> names
names = ["conv1_1.weight","conv1_1.bias", "conv1_2.weight", "conv1_2.bias", "conv2_1.weight", "conv2_1.bias", "conv2_2.weight", "conv2_2.bias", "conv3_1.weight", "conv3_1.bias", "conv3_2.weight", "conv3_2.bias", "conv3_3.weight", "conv3_3.bias", "conv4_1.weight", "conv4_1.bias", "conv4_2.weight", "conv4_2.bias", "conv4_3.weight", "conv4_3.bias", "conv5_1.weight", "conv5_1.bias", "conv5_2.weight", "conv5_2.bias", "conv5_3.weight", "conv5_3.bias", "fc6.weight", "fc6.bias", "fc7.weight", "fc7.bias", "fc8.weight", "fc8.bias"]
post_names = ["features.conv_1_1.weight", "features.conv_1_1.bias", "features.conv_1_2.weight", "features.conv_1_2.bias", "features.conv_2_1.weight", "features.conv_2_1.bias", "features.conv_2_2.weight", "features.conv_2_2.bias", "features.conv_3_1.weight", "features.conv_3_1.bias", "features.conv_3_2.weight", "features.conv_3_2.bias", "features.conv_3_3.weight", "features.conv_3_3.bias", "features.conv_4_1.weight", "features.conv_4_1.bias", "features.conv_4_2.weight", "features.conv_4_2.bias", "features.conv_4_3.weight", "features.conv_4_3.bias", "features.conv_5_1.weight", "features.conv_5_1.bias", "features.conv_5_2.weight", "features.conv_5_2.bias", "features.conv_5_3.weight", "features.conv_5_3.bias", "fc.fc6.weight", "fc.fc6.bias", "fc.fc7.weight", "fc.fc7.bias", "fc.fc8.weight", "fc.fc8.bias"]
from collections import OrderedDict
new_state_dict = OrderedDict()
for i in range(0,len(state_dict)):
name = names[i]
new_state_dict[name] = state_dict[post_names[i]]
return new_state_dict
def vgg_face(weights_path=None, **kwargs): # 实例化模型,weights_path=None 表示随机初始化权重
"""
load imported model instance
Args:
weights_path (str): If set, loads model weights from the given path
"""
model = Vgg_face_dag()
if weights_path:
state_dict = torch.load(weights_path)
new_state_dict = transform_key(state_dict)
model.load_state_dict(new_state_dict)
model.eval()
return model
vggface = vgg_face(weights_path= r"D:\Dataset\models\vggface.pth") # 实例化模型, weights_path 是权重文件路径